
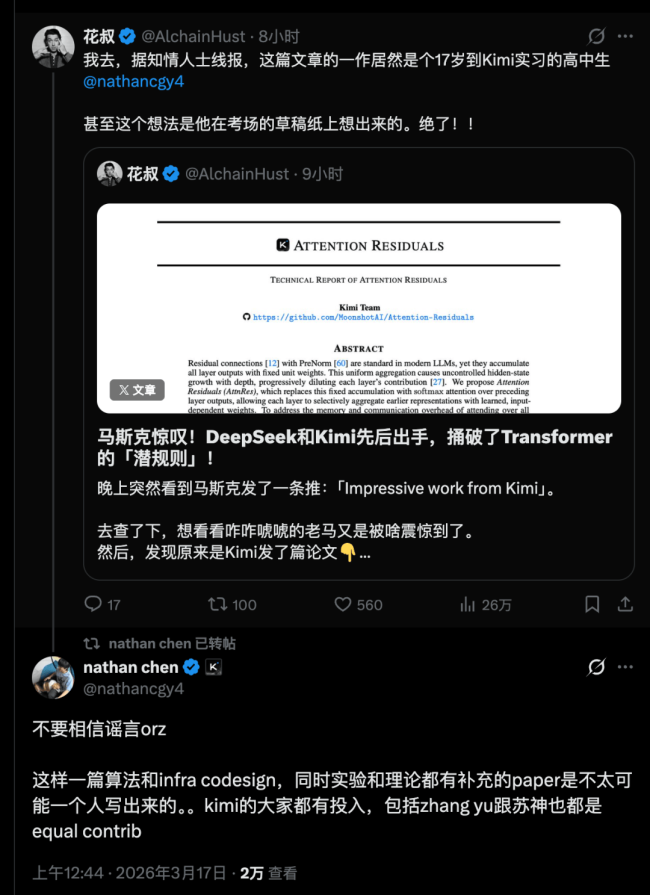
深圳17岁高三生成Kimi论文第一作者 创新机制引马斯克关注。一篇关于Transformer模型的论文引起了广泛关注,包括马斯克和Karpathy在内的多位专家都对其表达了浓厚兴趣。该论文提出了一种新的机制——Attention Residuals,通过在Kimi Linear 48B大模型上验证,训练效率提升了25%,而推理延迟仅增加了不到2%。

残差连接的传统工作原理是将第N层的输出设置为第N层的计算结果加上第N-1层的输出。然而,在大模型PreNorm主流范式下,这种做法会导致所有层的信息被等权重累加,从而引发“记忆负担”问题。具体表现为早期信息难以检索,且大量层可以被剪枝而损失微小,这被称为“PreNorm dilution problem”。此外,隐藏状态的范数会随着网络深度不断增长,导致训练不稳定。
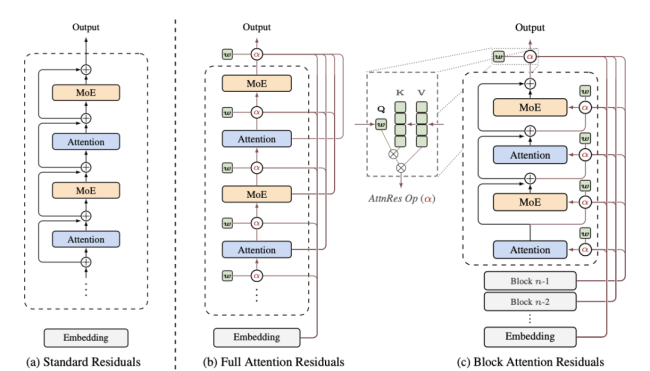
研究团队提出了一个新的思路:既然问题在于无差别累加,那么可以让网络自己决定需要回忆什么。他们发现,网络的深度维度与序列的时间维度本质上是同构的。因此,就像Transformer处理序列时使用注意力机制让当前位置选择性关注之前的位置一样,也可以让当前层选择性关注之前的层。这种方法被称为Attention Residuals,它通过当前层的可学习伪查询向量作为query,所有前层的输出作为key和value,用注意力机制进行加权聚合,使网络能够学会哪些层的信息对当前计算最重要。

然而,这种方法也带来了计算量爆炸的问题。对于一个100层的网络,每一层都要对前面99层做full attention residual,复杂度达到O(L²),实际运行中不可行。为此,论文提出了Block AttnRes解决方案,即把连续的若干层打包成一个block,每个block结束时将内部信息压缩成单个向量。这样,后续层只需要关注块间表征和块内实时层输出,而非全部L个层,从而将attention的复杂度降至O(L·B)。
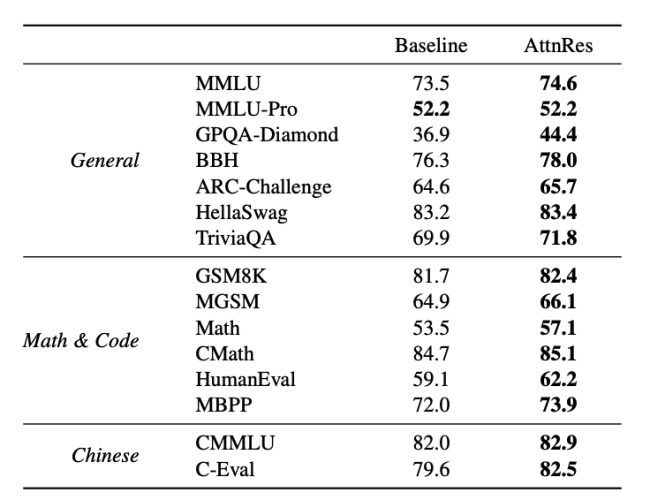
实验结果显示,在Kimi Linear架构上测试时,Attention Residuals能获得更好的下游性能,减少了约20%的训练计算量,相当于获得了1.25倍的效率优势。数学推理、代码生成及多语言理解任务上的表现均持平或略优。更重要的是,这一方法可以直接替换现有的残差连接,无需修改网络其他部分。
论文还提到了一个有趣的视角,即将这项工作称为“时间-深度对偶性”的应用。研究人员认为,深度神经网络的“层”和循环神经网络的“时间步”都是对信息的迭代处理。Transformer之所以成功,是因为用注意力机制替代了RNN中的固定recurrence。因此,在深度维度上,或许也应该用注意力机制替代固定的残差连接。
这篇论文的共同一作之一是一名年仅17岁的高中生陈广宇(Nathan)。他在北京的一场黑客松活动中展示了关于“人类第三只机械辅助手”的创新项目ThirdArm,并结识了创业导师董科含。随后,他开始接触IOI金牌得主及资深科研人员,逐步转向理解底层技术。在DeepSeek研究员袁境阳的指导下,他利用Gemini作为辅助工具,逐步建立了对Transformer的认知。最终,他加入月之暗面团队,参与了Flash Linear Attention项目,并在此过程中不断深入研究。
 个人配资平台
个人配资平台
米牛配资提示:文章来自网络,不代表本站观点。
相关文章



热点资讯
